如何写一个js模块打包器
前言
在看阮一峰老师的每周分享后,看到了一篇关于如何写一个模块打包器的一篇英文文章,之前基本没有了解过,只知道如何使用webpack等,所以这一篇对我来讲很及时,好记性不如烂笔头,所以先尝试着把它翻译出来。
人生已如此艰难,有些事情就不要拆穿(其实使用google翻译就好了)
这里先强烈安利一波:阮一峰老师的每周分享系列,可以了解很多新的东西,个人觉得非常nice,第一手的技术资讯网站:hacker news
原文
原文请看我 翻译错误处请大家指正
译文
让我们写个模块打包器
大家好!。。。(客套话)欢迎来到我的酒馆,今晚累的够呛,但只要有客人来玩我都欢迎(炉石手动滑稽,原文无此段)。今天我们将构建一个非常简单的js模块打包器。
在我们开始之前,我想确认下你们看了下面这些文章没有,本文依赖于此。
- Unbundling the JavaScript module bundler Luciano - Mammino
- Minipack - Ronen Amiel
好了,让我们开始了解模块打包器到底是什么?
什么是模块打包器
你可能用过像Browserify,Webpack,Rollup等工具,但一个模块打包器是一个获取js及其依赖项并将他们转换为单独的文件,通常使用在浏览器端。
它通常开始于入口文件,并从入口文件的依赖项中获取所有的代码
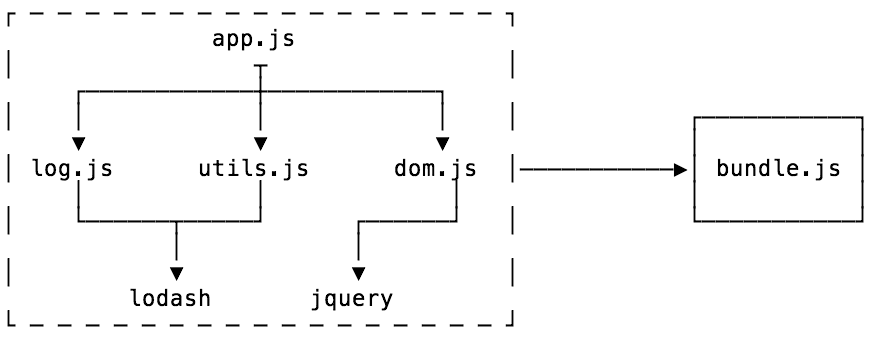
下面是打包器主要的两个阶段
- 依赖解析
- 打包
从入口点(上图中app.js)开始,依赖解析的目标是寻找你的代码中的所有依赖,也就是代码运行需要的其他代码片段,并构建出上图(依赖图)
一旦完成后,你就可以开始打包,或者将你的依赖图中的代码合并至一个你可以使用的文件中。
让我们开始导入一些我们的代码(我待会会给出原因)1
2
3
4const detective = require('detective')
const resolve = require('resolve').sync
const fs = require('fs')
const path = require('path')
依赖解析
我们要做的第一件事是思考在依赖解析阶段我们用什么来代表一个模块。
模块表示
我们需要下面四个东西
- 文件名字和文件标识
- 在文件系统中文件的位置
- 文件中的代码
- 该文件需要哪些依赖
依赖图的结构构建需要递归文件的依赖
在js中,最简单表示这一组数据的方式是一个对象,那么我们先这样做1
2
3
4
5
6
7
8let ID = 0
function createModuleObject(filepath) {
const source = fs.readFileSync(filepath, 'utf-8')
const requires = detective(source)
const id = ID++
return { id, filepath, source, requires }
}
看看createModuleObject方法,需要注意的是调用了一个detective的方法。detective是个一个库用于查找所有对require的调用,无论嵌套有多深,使用它意味着我们可以避免自己进行AST遍历得出文件的所有的依赖。
有一点需要注意(几乎在所有的模块打包器中都是一样的),如果你想做一些奇怪的事情
1 | const libName = 'lodash' |
依赖解析时将无法找到这个模块(因为这需要执行代码)
那么在给出一个模块后运行这个方法会等到什么呢?
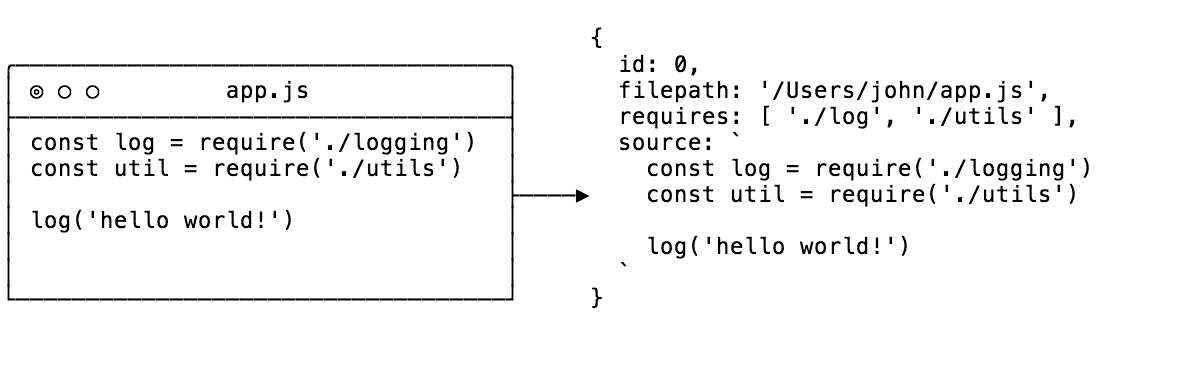
下一步是什么,依赖解析!!
好吧,还没到,我首先想要讲一个东西-模块图(module map)
模块图
当你在node引入模块时,你可以使用相对路径,比如require('./utils')。当你的代码执行到这时,打包器怎么知道正确的./utils文件在哪。
这是一个模块图解决的问题
我们的模块对象有一个id来标识来源,所以当我们开始依赖解析时,对于每一个模块,我们都将保留一份清单,列出所需的名字和id,所以在运行时我们可以等到正确的模块。
那意味着我们可以将所有模块存储在用id作为键的非嵌套对象中!
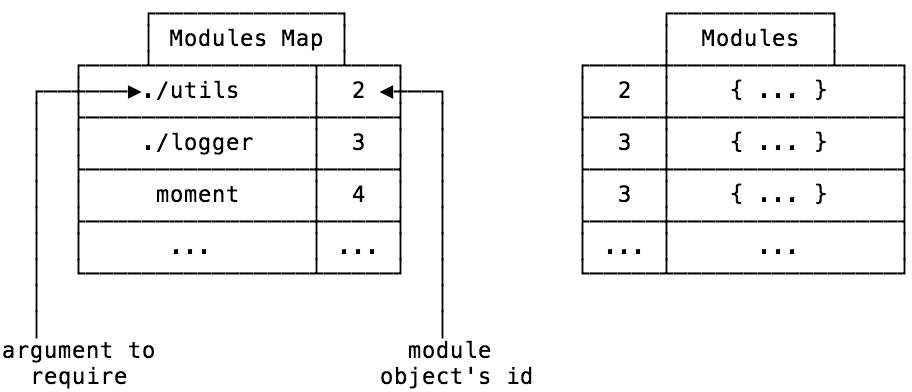
依赖解析
1 | function getModules(entry) { |
好的,getModules方法里面会有相当多的模块,这个方法主要用于从入口模块开始,以递归的方式查找和解析依赖项。
解析依赖是什么意思? 在node里有个东西叫require.resolve,这就是node怎么样找到你需要文件的位置的原因。这使得我们可以导入相对或者从node_modules中导入模块。
幸运的是,有一个叫resolve的npm模块可以为我们实现这样的算法,我们只需要把引入的文件和位置作为参数传递,它就可以帮我们完成其他复杂的工作。
所以我们开始解析项目中每一个模块的每一个依赖项
我们也可以构建我之前提到的模块图
在这个方法的最后,我们返回了一个叫modules的数组,里面存储了我们项目中每个模块/依赖项的模块对象。
打包
在浏览器中没有modules,这意味着没有require函数和module.exports,所以即使我们拿到了我们所需要的所有依赖项,也没把他们作为模块来使用。
模块工厂函数
工厂函数
工厂函数是一个返回对象的函数(不是构造函数),它是面向对象编程的模式,其用途之一是进行封装和依赖注入。
听上去不错?
使用工厂函数,我们要注入可以在打包后的代码中使用的require函数和module.exports对象,并且给出这个模块的作用域。
1 | // A factory function |
打包
我现在跟你展示打包方法,之后我会解释其余的。
1 | function pack(modules) { |
大多数都只是js模板语言,所以让我们来讨论它在做什么
首先是modulesSource,这里,我们将遍历每个模块,并将其转换为一串源代码。
那么一个模块对象最后会变成什么
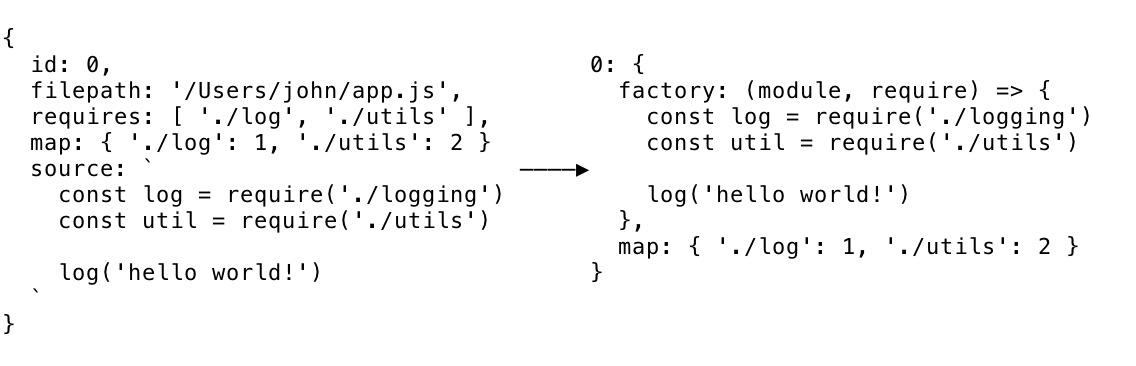
现在它有点难以阅读,但是你可以看到目标被封装了,我们为之前提到的factory函数提供了modules和require。
同时还包括了在依赖解析阶段我们构造的模块映射图
在下一步,我们把这些所有的依赖对象数组构建成了一个大的对象
下一串代码是IIFE(立即执行函数表达式),这意味你在浏览器或者别的地方运行代码时,这个函数将会被立即执行,IIFE是封装作用域的另外的一种模式,所以在这里我们担心require和moduels会污染全局作用域。
你也可以看到我们定义了两个require函数,require和localRequire。
require把模块对象的id作为参数,但源代码是没有id的,我们使用其他函数localRequire通过传入任何参数并转成正确的id来获取模块,正是通过模块图来实现的。
在这之后,我们定义了一个可以填充的模块对象,把对象和localRequire作为参数传入factory,然后返回module.exports。
最后,我们执行require(0)去引入id为0的模块作为我们的入口模块。
搞定,我们的模块打包器就已经完成了。
1 | module.exports = entry => pack(getModules(entry)) |
最后
所以我们现在已经拥有了一个模块打包器。
现在这个可能不能用于生产,因为它缺少了大量的功能(管理循环依赖,确保每个文件只被解析一次,es-modules等等),但希望能使你对模块打包器的实际工作方式有所了解。
实际上,你删除所有模块中的源代码,实现这个模块打包器才大约60行。
感谢阅读,希望您对我们这个简单的模块打包器如何工作有所了解
